树 | DS
树
概念
定义
唯一根结点与若干棵互不相交的子树组成(每一棵子树又是一棵树,递归定义)
是一种非线性的数据结构
属于分层结构
特点
根结点无前驱,其他所有结点有且只有一个前驱
所有结点可以有零个或多个后继
基本术语
空树、结点的度(结点的孩子个数)、树的度(树中结点的最大度数)、叶子/终端结点(度为 0)、分支/非终端结点(度大于 0)、内部结点、孩子、双亲、兄弟、祖先、子孙、层次(根结点为第 1 层)、树的高度/深度(树中结点的最大层数)、结点深度(自顶向下逐层累加)、结点高度(自底向上逐层累加)、堂兄弟(双亲在同一层)、有序树(各子树左右有序,不能互换)、无序树、路径(结点序列)、路径长度(路径上所经过的边的个数)、丰满树/理想平衡树(除最底层外其他层都是满的)、森林(若干棵互不相交的树的集合)
分支有向(双亲指向孩子),路径只能自顶向下,故同一双亲的两个孩子之间不存在路径
“路径长度”
结点的路径长度:根到该结点经过的边数
树的路径长度:所有结点的路径长度之和
结点的带权路径长度:该结点路径长度与其权值的乘积
树的带权路径长度 WPL:所有叶结点的带权路径之和
存储结构
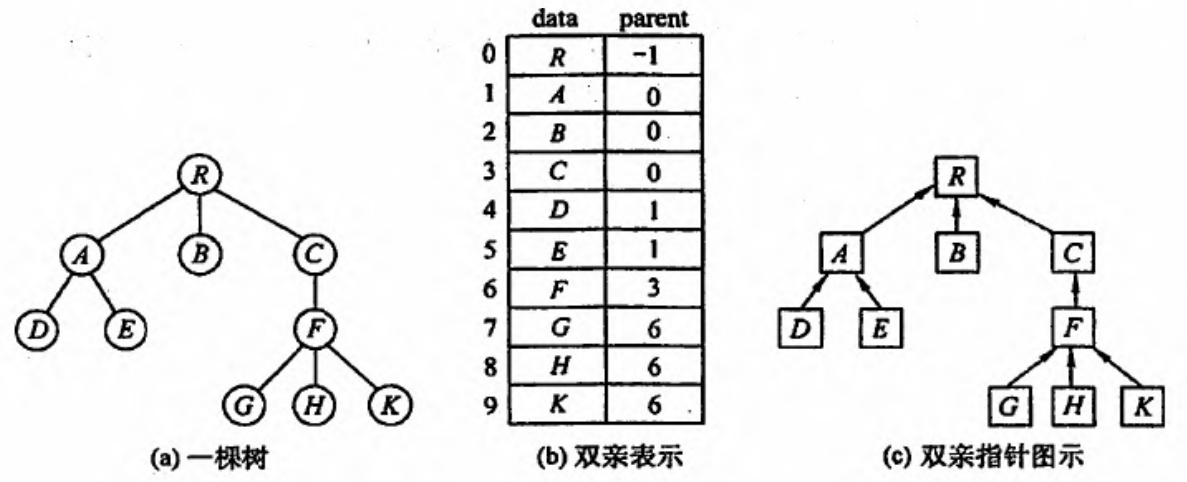
双亲表示法(顺序)
最简单直观
利用了每个结点(根结点除外)双亲唯一的性质,可以很快得到每个结点的双亲结点,但求结点的孩子时需要遍历整个结构
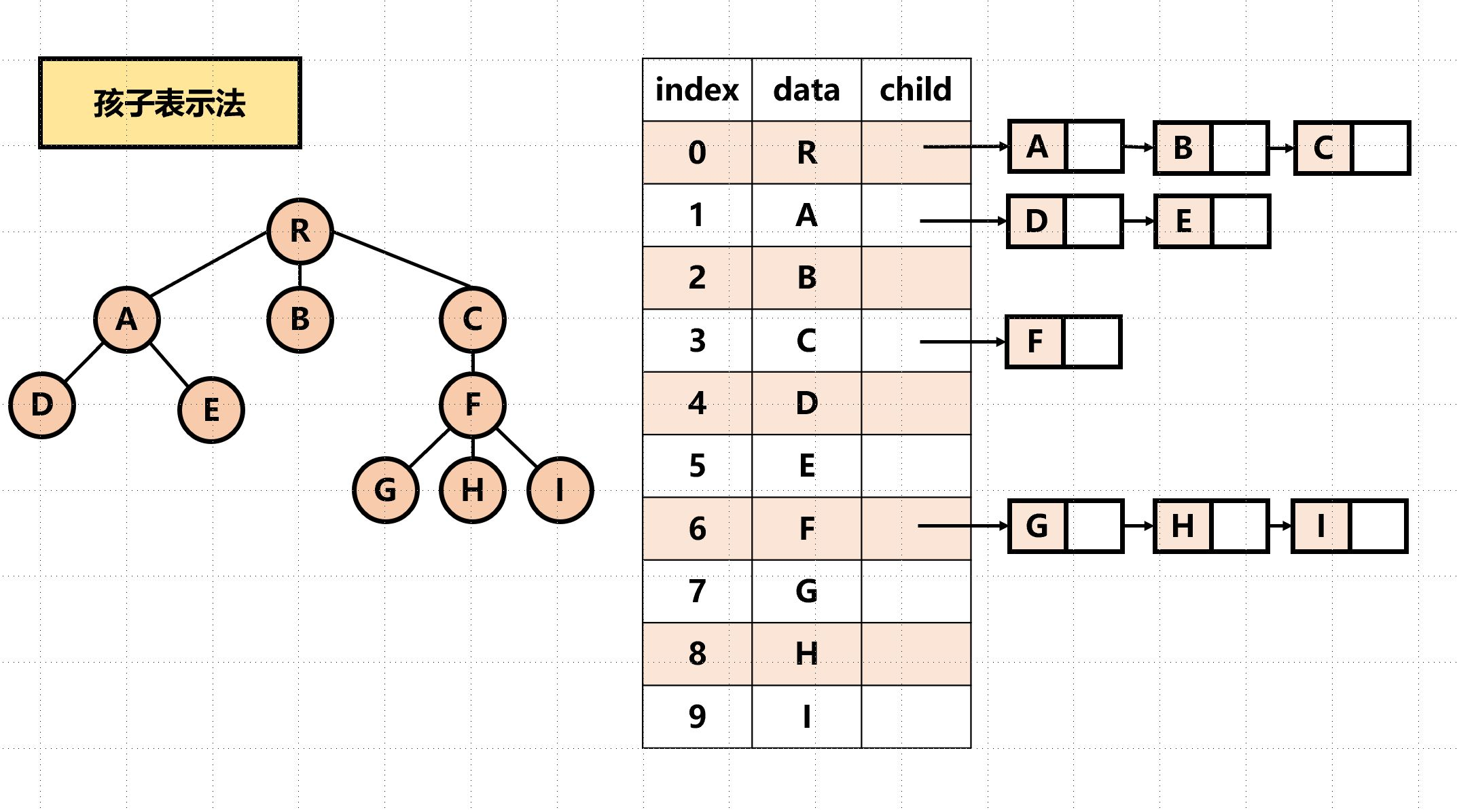
孩子表示法(链式)
实质是图的邻接表存储结构
找孩子简单,找双亲麻烦
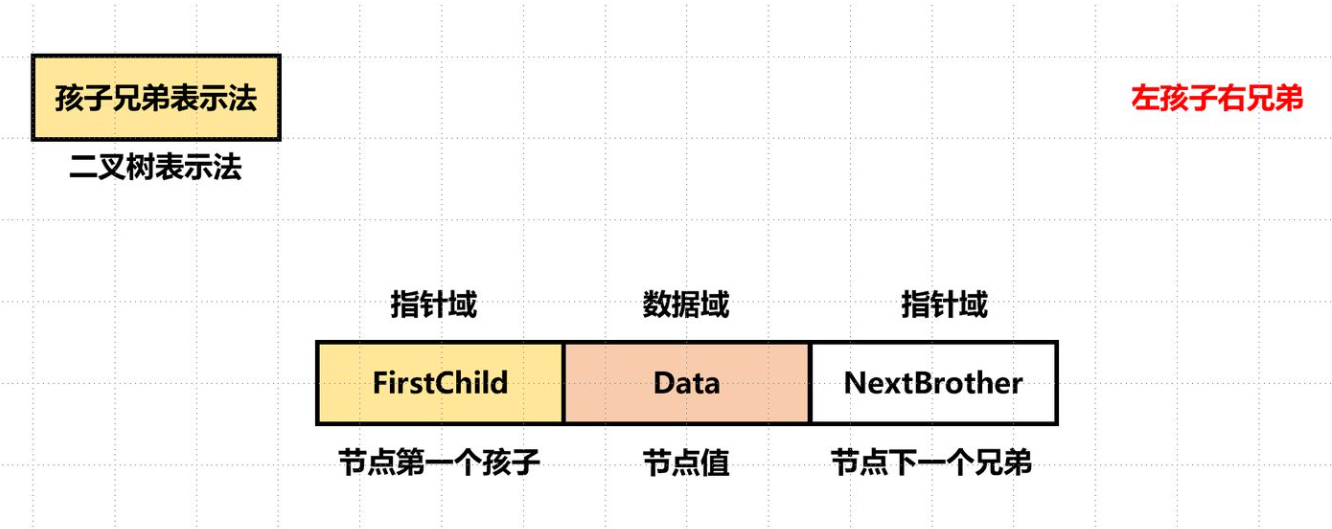
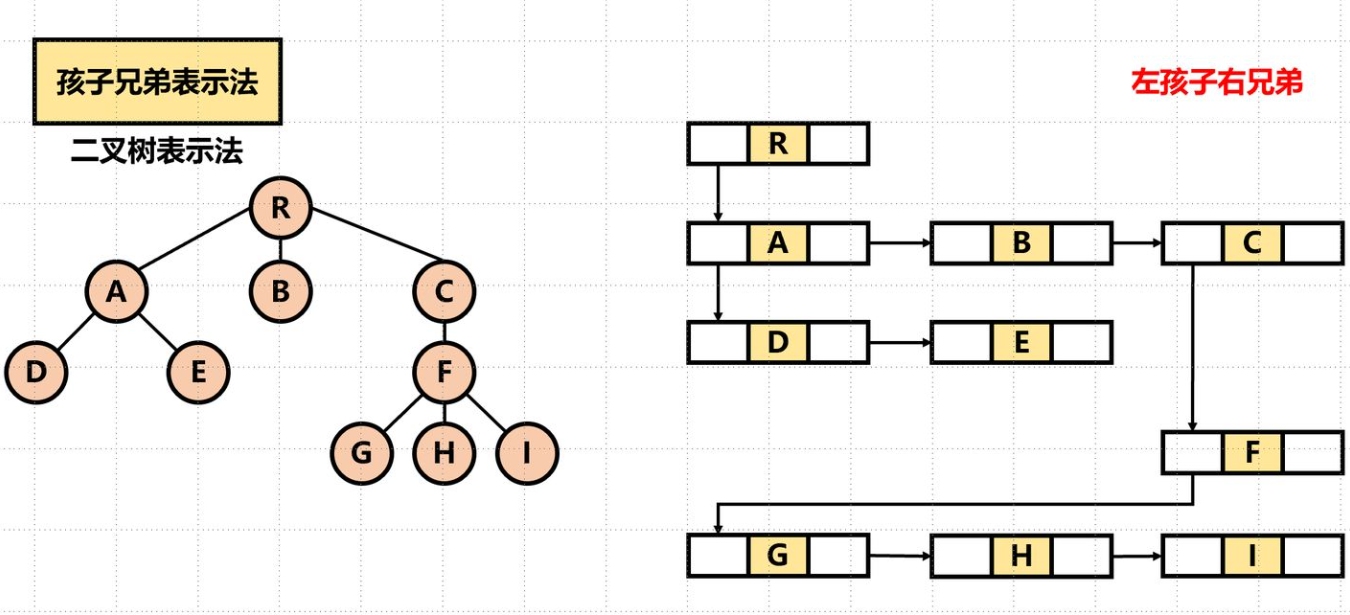
孩子兄弟表示法/二叉树表示法
可以方便地实现树转换为二叉树的操作、易于查找孩子等
找双亲也还是麻烦(除非再加个 parent 指针)
性质
总结点数 $n$ = 总分支数 + 1
$n = n_0+n_1+n_2+n_3+…+n_m = 1+n_1+2n_2+3n_3+…+mn_m$
$n_0=1+n_2+2n_3+…+(m-1)n_m$
度为 $m$ 的树中第 $i$ 层上至多有 $m^{i-1}$ 个结点
高度为 $h$ 的 $m$ 叉树至多有 $(m^h-1)/(m-1)$ 个结点
具有 $n$ 个结点的 $m$ 叉树的最小高度为 $\lceil \log_m(n(m-1)+1) \rceil$
二叉树
概念
定义(对树的限制)
每个结点最多两棵子树
子树有左右之分(次序不能任意颠倒)
基本形态(5 种)
空二叉树、只有根结点、只有左子树、只有右子树、左右子树都有
二叉树 vs 度为 2 的有序树
1)二叉树是度最多为 2,可为空;度为 2 的有序树至少有 3 个结点
2)二叉树的结点次序不是相对于另一结点而言,而是确定的;有序树的结点次序是相对于另一结点而言的,如果有序树中的子树只有一个孩子,那这个孩子结点就无须区分其左右次序
二叉树性质
$n = n_0+n_1+n_2 = 1+n_1+2n_2$
$n_0=1+n_2$
第 $i$ 层最多 $2^{i-1}$ 个结点($i≥1$)
高度/深度为 $k$ 的二叉树最多有 $2^{k}-1$ 个结点($k≥1$)
具有 $n$ ($n≥1$) 个结点的完全二叉树的高度/深度为 $\left\lceil\log _2(n+1)\right\rceil$ 或 $\left\lfloor\log _2 n\right\rfloor+1$
含有 $n$ 个结点的二叉链表中含有 $2n-(n-1) = n+1$ 个空链域
特殊的二叉树
1)满二叉树:高度为 $h$,且含有 $2^h-1$ 个结点的二叉树
2)完全二叉树:对应相同高度的满二叉树缺失最下层最右边的一些连续叶结点
3)二叉排序树:左子树所有结点的关键字均小于根结点的关键字;右子树所有结点的关键字均大于根结点的关键字;左右子树又各是一棵二叉排序树
4)平衡二叉树:任意一个结点的左右子树深度之差不超过 1
完全二叉树特点
对于有 $n$ 个结点的完全二叉树,$i$ 为某结点 $a$ 的编号(从上到下、从左到右依次编号 $1,2,…,n$)
若 $i≠1$,则 $a$ 双亲结点编号 $\lfloor i / 2\rfloor$
若 $2i≤n$,则 $a$ 左孩子标号为 $2i$
若 $2i+1≤n$,则 $a$ 右孩子标号为 $2i+1$
若 $i ≤ \lfloor n / 2\rfloor$,则结点 $i$ 为分支结点,否则为叶结点
若 $n$ 为奇数,则每个分支结点都有左孩子右孩子;若 $n$ 为偶数,则编号最大的分支结点(编号为 $n/2$)只有左孩子,其余分支结点都有左孩子右孩子
叶结点只可能在层次最大的两层出现。对于最大层次中的叶结点,都依次排列在该层最左边的位置上
若有度为 1 的结点,则只可能有一个,且该结点只有左孩子
一旦出现某结点为叶结点或只有左孩子,则编号大于该结点的结点均为叶结点
存储结构
顺序存储结构
用一组地址连续的存储单元依次自上而下、自左至右存储完全二叉树上的结点元素
建议从数组下标 1 开始存储树中的结点(可利用完全二叉树特点 1)
完全二叉树和满二叉树比较合适
链式存储结构
二叉链表,结点至少三个域:数据域、左指针域、右指针域
在含有 $n$ 个结点的二叉链表中,含有 $n+1$ 个空链域
遍历
按照先遍历左子树后右子树的原则,常见的遍历次序有先序 NLR、中序 LNR 和后序 LRN 三种,其中“序”指的是根结点何时被访问
先序遍历
第一个结点:根结点
最后一个结点:最右叶结点
规律:祖先先访问(直系),同辈则最左
中序遍历
第一个结点:最左
最后一个结点:最右
遍历规律:左方先访问
后序遍历
第一个结点:最左叶结点
最后一个结点:根结点
遍历规律:子孙先访问(直系),同辈则最左
统一规律:左子树 → 右子树,所有叶结点顺序相同
知先序,找不可能的中序
观察法:在中序划根,得到当前根的左右子树,边划边结合先序
根据前序序列和中序序列的关系:以先序序列为入栈次序,中序序列为出栈次序
知先后
可推祖先和子孙关系:先序 X……Y,后序 Y……X,则 X 是 Y 祖先(X、Y 可以是一坨结点)
先后序列完全相反 $\rightarrow$ 二叉树高度等于结点数
使用后序遍历可以得到祖先到子孙的路径
先序/后序/层次 + 中序,可唯一确定一棵二叉树
先序 NLR 与后序 LRN 相反:L 或 R 为空,每层只有一个结点(即该二叉树高度等于其结点数/只有一个叶结点)
先序 NLR 与后序 LRN 相同:L、R 都空(即只有根结点)
先序 NLR 与中序 LNR 相同:所有非叶结点没有左子树
给定 $n$ 个结点的先序序列,可以构成 $h(n)=\frac{C^n_{2n}}{n+1}$ 种不同的二叉树
线索二叉树
规定:若无左子树,就令 lchild 指向其前驱结点;若无右子树,就令 rchild 指向其后继结点。每个结点还需增加两个标志域标识指针域是指向孩子还是线索。线索二叉树是物理结构
引入目的:加快查找结点前驱和后继的速度(前驱后继源自深度优先遍历)
实现基础:在含 $n$ 个结点的二叉树中,有 $n+1$ 个空指针,利用这些空链域来存放指向其前驱或后继的指针,这样就能像遍历单链表那样方便地遍历二叉树
原 $n+1$ 个空链域全部成为了线索(但线索仍可能是空链域)
线索化的实质:深度遍历
二叉树线索化后仍不能解决:先序求前驱、后序求后继
中序前驱:左线索/左子树最右结点
中序后继:右线索/右子树最左结点
先序前驱:为其双亲(自己为双亲的左孩子或自己为双亲的右孩子但无左兄弟时)或是左兄弟树最右叶结点(自己为双亲的右孩子且有左兄弟时)。都需要找到双亲,要是自己有左孩子(即无左线索),就无法找到
先序后继:左孩子/右孩子/右线索
后序前驱:右孩子/左孩子/左线索
后序后继:(除了根结点后继为空的情况)为其双亲(自己为双亲的右孩子或自己为双亲的左孩子但无右兄弟时)或是右兄弟树最左叶结点(自己为双亲的左孩子且有右兄弟时)。都需要找到双亲,要是自己有右孩子(即无右线索),就无法找到
可见先序求前驱、后序求后继都需要找到双亲结点。可采用三叉链表解决,即每个结点内增加一个指向双亲结点的指针,或借助栈的支持
同理,后序线索二叉树的遍历需要采用三叉链表或栈的支持
中序线索二叉树的遍历
需要两个算法:
1)找到中序序列中的第一个结点(最左结点)
2)找到某结点在中序序列下的后继(右线索/右子树最左结点)
带头结点的中序线索二叉树
头结点 lchild 指向二叉树根结点,rchild 指向中序遍历时访问的最后一个结点,同时令中序序列第一个结点的 lchild 和最后一个结点的 rchild 均指向头结点
这好比为二叉树建立了一个双向循环线索链表,方便从前往后或从后往前对线索二叉树进行遍历
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342/* 二叉树结点(链式) */
typedef struct BTNode {
ElemType data;
struct BTNode *lchild, *rchild;
} BTNode, *BTree;
/**
* 先序遍历NLR(递归)
*/
void preOrder(BTree t) {
if (t == NULL) return;
visit(t);
preOrder(t->lchild);
preOrder(t->rchild);
}
/**
* 中序遍历LNR(递归)
*/
void inOrder(BTree t) {
if (t == NULL) return;
inOrder(t->lchild);
visit(t);
inOrder(t->rchild);
}
/**
* 后序遍历LRN(递归)
*/
void postOrder(BTree t) {
if (t == NULL) return;
postOrder(t->lchild);
postOrder(t->rchild);
visit(t);
}
/**
* 先序遍历(非递归)
*/
void preOrderNonrecursion(BTree t) {
SqStack st;
initStack(st);
BTNode *p = t;
while (p || !isEmpty(st)) {
if (p) {
visit(p);
push(st, p);
p = p->lchild;
} else {
pop(st, p);
p = p->rchild;
}
}
}
/**
* 中序遍历(非递归)
*/
void inOrderNonrecursion(BTree t) {
SqStack st;
initStack(st);
BTNode *p = t;
while (p || !isEmpty(st)) {
if (p) {
push(st, p);
p = p->lchild;
} else {
pop(st, p);
visit(p);
p = p->rchild;
}
}
}
/**
* 后序遍历(非递归)
*/
void postOrderNonrecursion(BTree t){
SqStack st;
initStack(st);
BTNode *p = t;
BTNode *r = NULL; // 跟踪上一次访问的结点
while (p || !isEmpty(st)) {
if (p) { // 一路向左
push(st, p);
p = p->lchild;
} else {
getTop(st, p);
if (p->rchild && p->rchild != r) { // 右拐一下
p = p->rchild;
} else { // 左右都走不了,那就访问
pop(st, p);
visit(p);
r = p;
p = NULL; // 访问完需要重置p指针
}
}
}
}
/**
* 层次遍历
*/
void levelOrder(BTree t) {
if (t == NULL) return;
SqQueue qu;
initQueue(qu);
enQueue(qu, t);
BTNode *p;
while (!isEmpty(qu)) {
deQueue(qu, p);
visit(p);
if (p->lchild) enQueue(qu, p->lchild);
if (p->rchild) enQueue(qu, p->rchild);
}
}
/* 线索二叉树 */
tpyedef struct TBTNode {
ElemType data;
struct TBTNode *lchild, *rchild;
int ltag, rtag;
} TBTNode, *TBTree;
/* 中序线索二叉树 */
/**
* 通过中序遍历(递归)对二叉树线索化
* @param p 当前访问的结点
* @param pre 上一个访问的结点
*/
void inThread(TBTNode *&p, TBTNode *&pre) {
if (p == NULL) return;
// 线索化左子树
inThread(p->lchild, pre);
// 建立当前结点前驱线索
if (p->lchild == NULL) {
p->lchild = pre;
p->ltag = 1;
}
// 建立前驱结点后继线索
if (pre != NULL && pre->rchild == NULL) {
pre->rchild = p;
pre->rtag = 1;
}
// 当前结点处理完毕,标记成为上一个访问的结点
pre = p;
// 线索化右子树
inThread(p->rchild, pre);
}
/**
* 通过中序遍历建立中序线索二叉树
*/
void createInThread(TBTree t) {
if (t == NULL) return;
TBTNode* pre = NULL;
// 中序遍历线索化二叉树
inThread(t, pre);
// 处理最后一个结点
pre->rchild = NULL;
pre->rtag = 1;
}
/**
* 求中序线索二叉树中中序序列下的第一个结点
* @param p 中序线索二叉树根结点
* @return 目标结点
*/
TBTNode *firstNodeIn(TBTNode *p) {
while (p->ltag == 0) {
p = p->lchild; // 即最左结点
}
return p;
}
/**
* 求中序线索二叉树中中序序列下的最后一个结点
* @param p 中序线索二叉树根结点
* @return 目标结点
*/
TBTNode *lastNodeIn(TBTNode *p) {
while (p->rtag == 0) {
p = p->rchild; // 即最右结点
}
return p;
}
/**
* 求中序线索二叉树中结点在中序序列下的前驱
* @param p 中序线索二叉树某结点
* @return p的前驱结点
*/
TBTNode *priorNodeIn(TBTNode *p) {
if (p->ltag == 1) {
return p->lchild; // 有线索
} else {
return lastNodeIn(p->lchild); // 左子树最右结点
}
}
/**
* 求中序线索二叉树中结点在中序序列下的后继
* @param p 中序线索二叉树某结点
* @return p的后继结点
*/
TBTNode *nextNodeIn(TBTNode *p) {
if (p->rtag == 1) {
return p->rchild; // 有线索
} else {
return firstNodeIn(p->rchild); // 右子树最左结点
}
}
/**
* 中序线索二叉树的中序遍历
*/
void inOrder(TBTree t) {
for (TBTNode *p = firstNodeIn(t); p != NULL; p = nextNodeIn(p)) {
visit(p);
}
}
/* 先序线索二叉树 */
/**
* 通过先序遍历对二叉树线索化
* @param p 当前访问的结点
* @param pre 上次访问的结点
*/
void preThread(TBTNode *&p, TBTNode *&pre) {
if (p == NULL) return;
// 建立当前结点前驱线索
if (p->lchild == NULL) {
p->lchild = pre;
p->ltag = 1;
}
// 建立前驱结点后继线索
if (pre != NULL && pre->rchild == NULL) {
pre->rchild = p;
pre->rtag = 1;
}
// 标记当前结点成为上一个访问过的结点
pre = p;
// 线索化左子树
preThread(p->lchild, pre);
// 线索化右子树
preThread(p->rchild, pre);
}
/**
* 求先序线索二叉树中结点在先序序列下的前驱
* 为其双亲或是左兄弟子树最右叶结点
* 都需要找到双亲,要是有左孩子就无法找到
*/
/**
* 求先序线索二叉树中结点在先序序列下的后继
*/
TBTNode *nextNodePre(TBTNode *p) {
return p->ltag == 0 ? p->lchild : p->rchild;
}
/**
* 先序线索二叉树的先序遍历
*/
void preOrder(TBTree t) {
if (t != NULL) {
TBTNode *p = T;
while (p != NULL) {
while (p->ltag == 0) { // 一路向左
visit(p);
p = p->lchild;
}
visit(p);
p = p->rchild;
}
}
}
/**
* 通过后序遍历对二叉树线索化
* @param p 正在访问的结点
* @param pre 刚刚访问过的结点
*/
void postThread(TBTNode *p, TBTNode *&pre) {
if (p == NULL) return;
// 线索化左子树
postThread(p->lchild, pre);
// 线索化右子树
postThread(p->rchild, pre);
// 建立当前结点的前驱线索
if (!p->lchild) {
p->lchild = pre;
p->ltag = 1;
}
// 建立前驱结点的后继线索
if (pre && !pre->rchild) {
pre->rchild = p;
pre->rtag = 1;
}
// 标记当前结点成为上一个访问过的结点
pre = p;
}
/**
* 求后序线索二叉树中结点p在后序序列下的前驱
*/
TBTNode *priorNodePost(TBTNode *p) {
return p->rtag == 0 ? p->rchild : p->lchild;
// 有右孩子 → 右孩子
// 无右孩子但有左孩子 → 左孩子
// 左右孩子都无 → 左链域(线索)
}
/**
* 求后序线索二叉树中结点在后序序列下的后继
* 为其双亲或是右兄弟子树最左叶结点
* 都需要找到双亲,要是有右孩子就无法找到
*/
/**
* 后序线索二叉树的后序遍历
* 后继不一定找得到,可以给结点增加指向双亲的指针域或借助栈
*/树、森林
转换
树 → 二叉树
兄弟结点之间连线、每个结点只保留它与第一个孩子的连线、以树根为轴顺时针旋转 45°(孩子兄弟表示法)
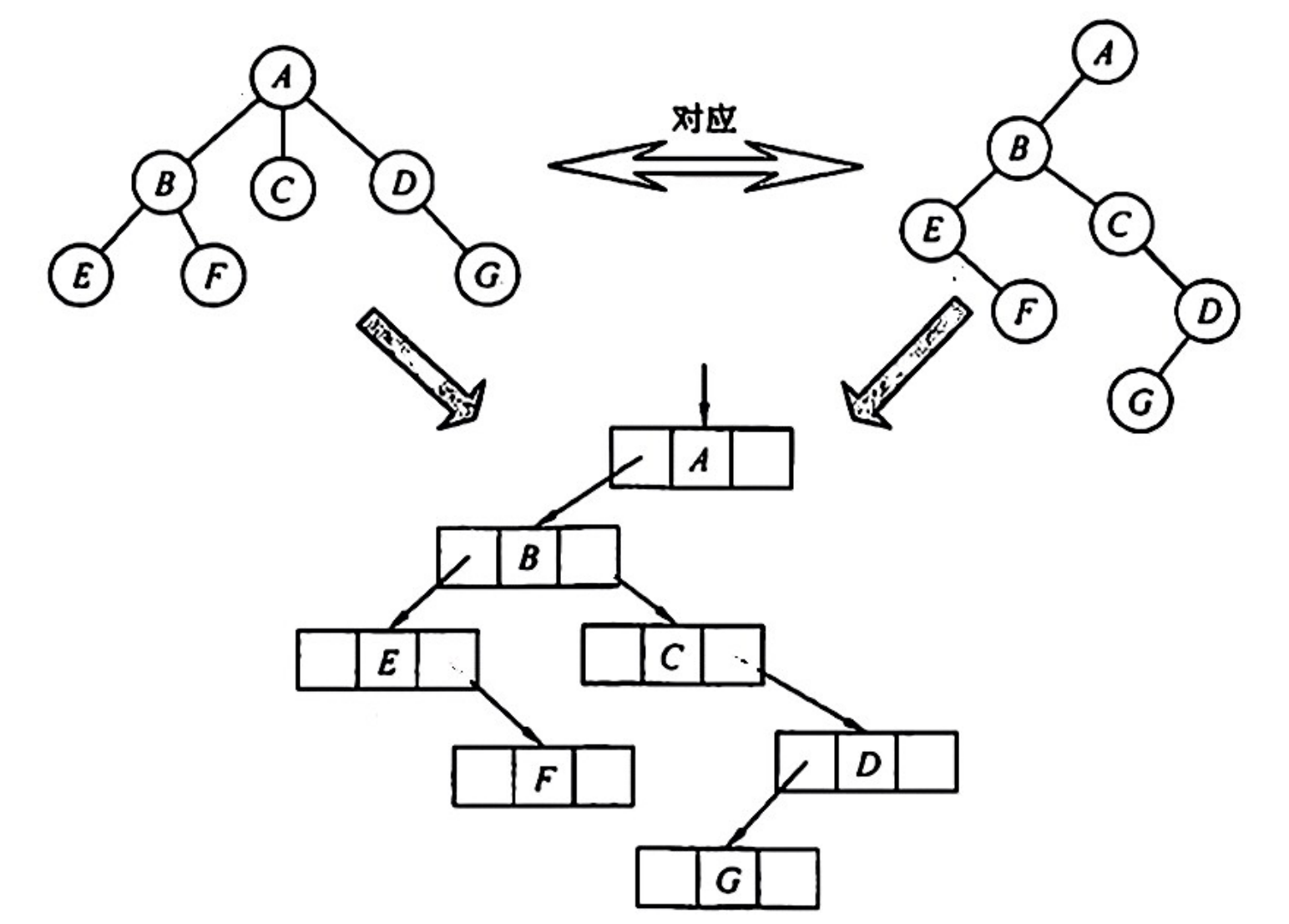
根结点右子树必为空
二叉树 → 树
调整水平,连层间,去层内
森林 → 二叉树
每棵树先转成二叉树,最后每棵二叉树的根结点从左往右依次连接
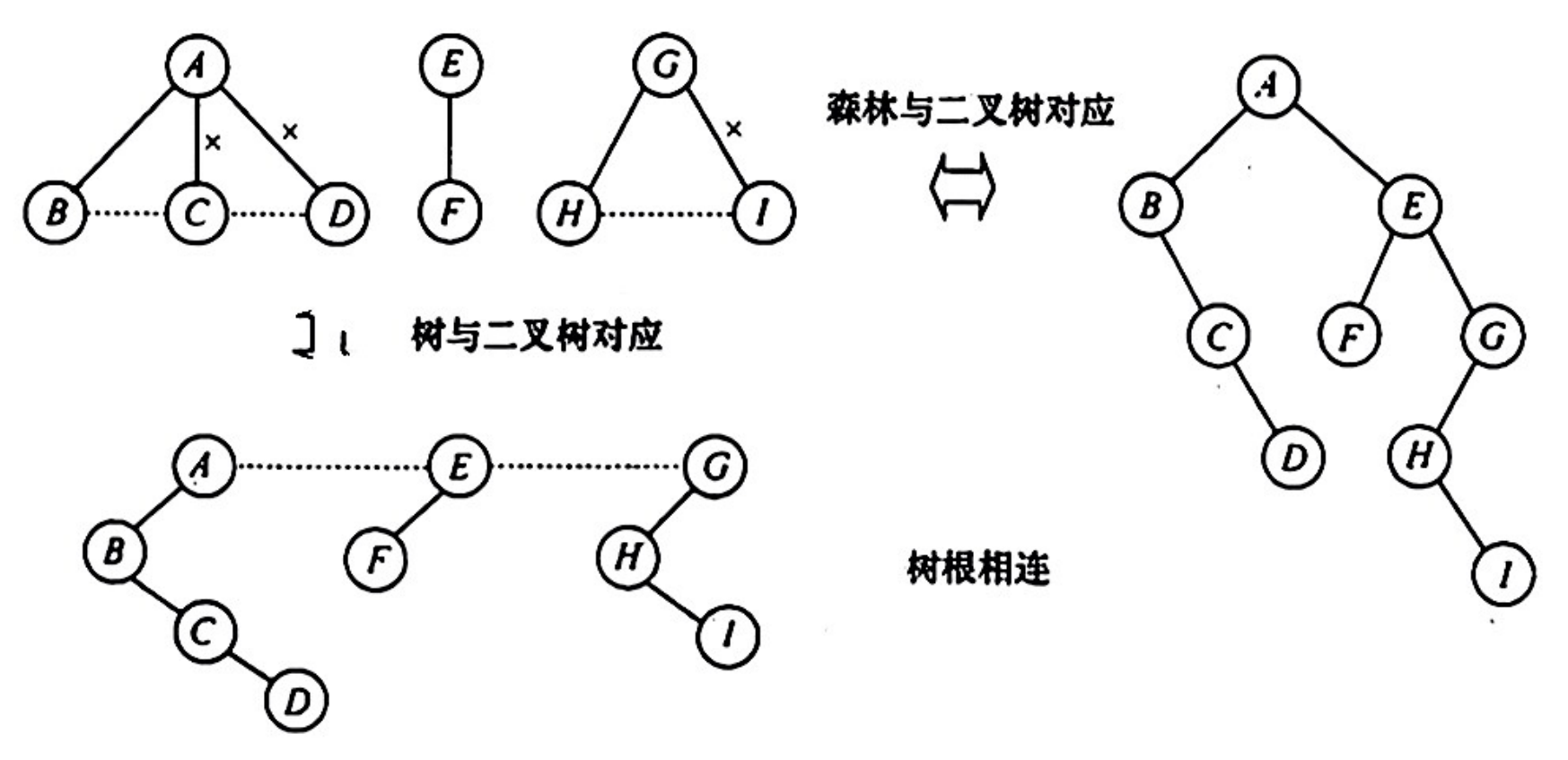
二叉树 → 森林
根的右链依次断开,拆成若干没有右子树的二叉树,然后再将这些二叉树转成树
遍历
树的遍历
先根遍历:先根后子树。其遍历序列与对应二叉树的先序序列相同
后根遍历:先子树后根。其遍历序列与对应二叉树的中序序列相同
层序遍历:从上往下按层
森林的遍历
先序遍历:从左往右依次先根遍历每棵树。其遍历序列与对应二叉树的先序序列相同
中序遍历/后序遍历:从左往右依次后根遍历每棵树。其遍历序列与对应二叉树的中序序列相同
称中序遍历是相对于其对应二叉树而言;称后序是因为根是最后访问的
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/* 树(双亲表示法) */
/**
* 结点
*/
typedef struct {
ElemType data;
int parent;
} TNode;
/**
* 树
*/
typedef struct {
TNode nodes[MAX_TREE_SIZE];
int n;
} Tree;
/* 树(孩子兄弟表示法/二叉树表示法) */
typedef struct CSNode {
ElemType data;
struct CSNode *firstChild, *nextSibling; // 第一个孩子和右兄弟指针
} CSNode, *CSTree;应用
哈夫曼树和哈夫曼编码
权:在许多应用中,树中结点常常被赋予一个表示某种意义的数值,称为该结点的权
结点的带权路径长度:从树的根到任意结点的路径长度(经过的边数)与该结点上权值的乘积
树的带权路径长度:树中所有叶结点的带权路径长度之和
哈夫曼树/最优二叉树
带权路径最小的树
哈夫曼树的构造
1)找权值最小的 $k$ 个根作为子树构成一棵新的 $k$ 叉树,该 $k$ 叉树根结点的权值为其子树根结点权值之和
2)重复第一步,直到只剩下一棵 $k$ 叉树
当初始叶结点个数 $n_0$ 满足 $u = (n_0 - 1) \% (k - 1) = 0$ 时才可构造出 $k$ 叉哈夫曼树。当不满足时,需补上 $k-1-u$ 个权值为 $0$ 的虚叶结点
每构造 1 个度为 $k$ 的结点,就会少 $k - 1$ 坨结点,直到最后剩下一大坨结点
哈夫曼 $k$ 叉树的特点
1)所有初始结点最终都成为叶结点,且权值越大的结点离根结点越近
2)其结点的度只有 $0$ 与 $k$ 两种 → 正则/严格 $k$ 叉树,$n_0 = 1+(k-1)n_k$
3)树的带权路径长度最短(WPL 最小)
4)孩子结点权值之和等于父结点权值
5)哈夫曼树任一分支结点的权值一定不小于下一层任一结点的权值
对应一组权值构造出来的哈夫曼树一般不是唯一的:左右孩子结点的顺序是任意的
此外,如有若干权值相同的结点,则构造出的哈夫曼树更可能不同
但 WPL 必然相同且是最优的
哈夫曼编码
特点:
1)可变长度:允许对不同字符用不等长的二进制位表示
2)数据压缩:可变长度编码对频率高的字符赋以短编码,而对频率较低的字符赋以较长一些的编码,从而可以使字符的平均编码长度减短,起到压缩数据的效果
3)前缀编码:没有一个编码是另一个编码的前缀
由哈夫曼树构造哈夫曼编码的示例:
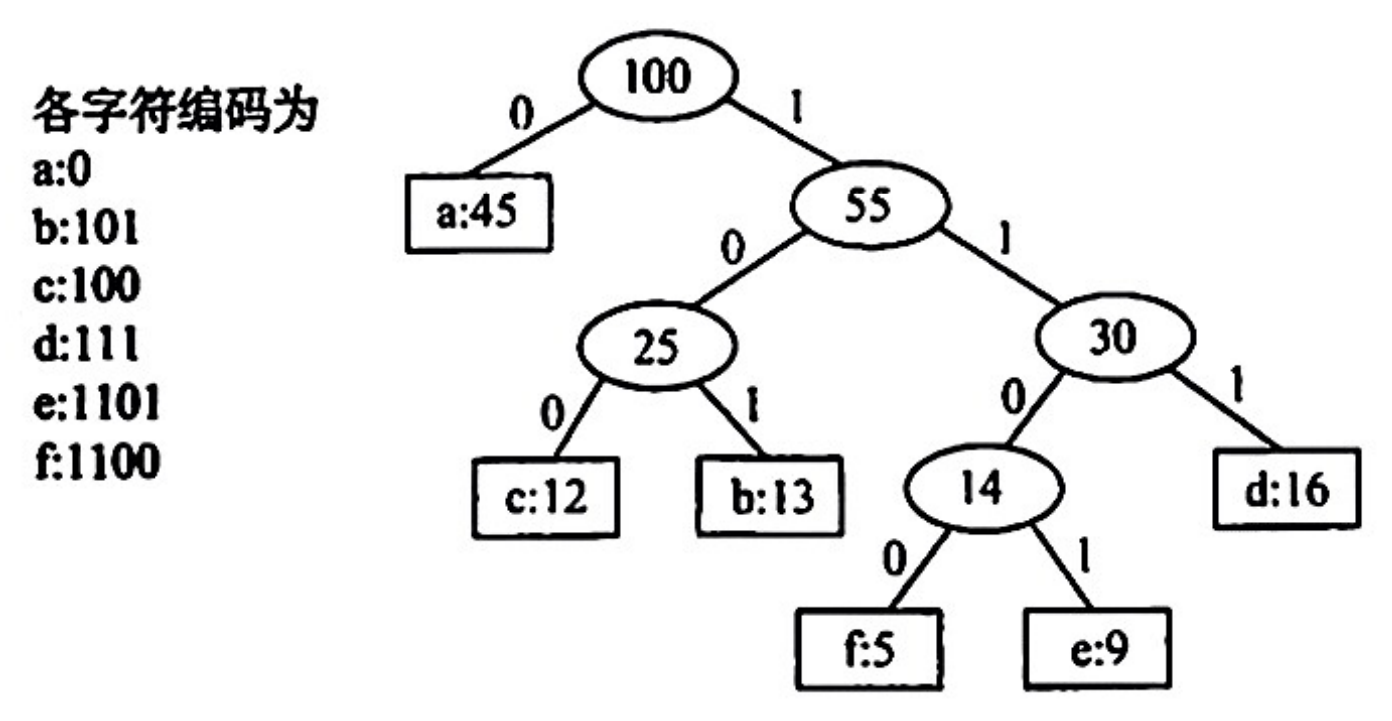
将每个字符当作一个独立的结点,其权值为它出现的频率或次数,构造出对应的哈夫曼树。显然所有字符结点都出现在叶结点中。可将字符的编码解释为从根至该字符路径上边标记的序列,其中边标记为 0 表示”转向左孩子“,边标记为 1 表示”转向右孩子“
并查集
一种简单的集合表示
支持以下 3 种操作:
initial(S):将集合 S 中的每个元素都初始化为只有一个单元素的子集合
union(S, Root1, Root2):把集合 S 中的子集合 Root2 并入子集合 Root1
要求 Root1 和 Root2 互不相交,否则不执行合并
find(S, x):查找集合 S 中单元素 x 所在的子集合,并返回该子集合的根结点
通常使用树(森林)的双亲表示作为并查集的存储结构,通常用数组元素的下标代表元素名,用根结点的下标代表子集合名,根结点的双亲结点为负数
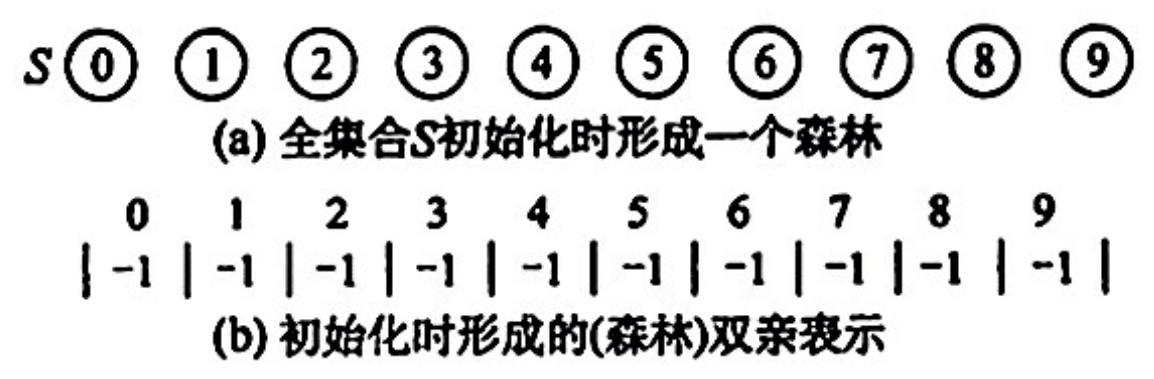
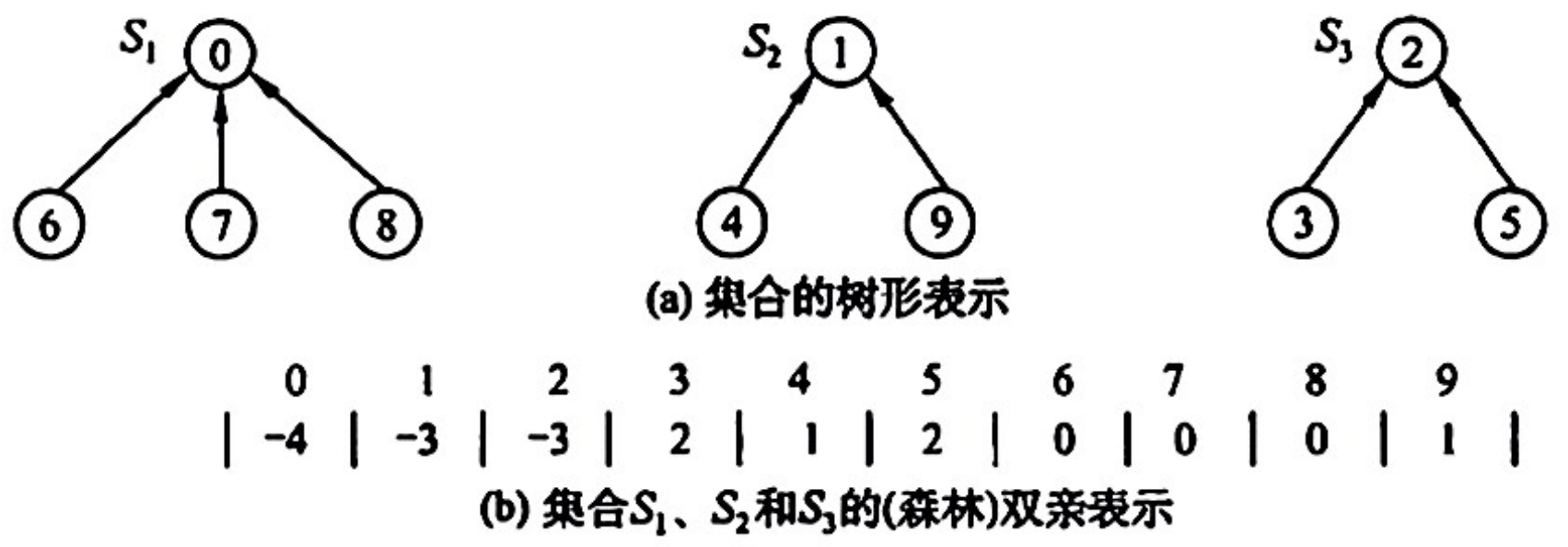
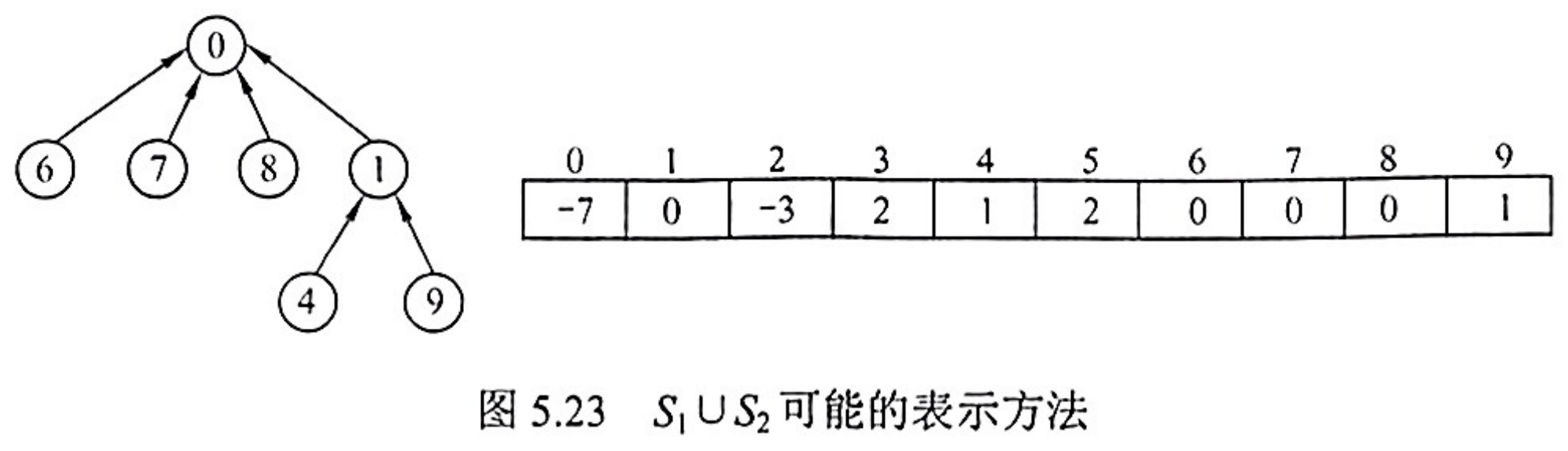
为了得到两个子集合的并,只需将其中一个子集合根结点的双亲指针指向另一个集合的根结点
刷题总结
完全二叉树只要知道总结点个数就能知道 $n_0$、$n_1$、$n_2$ 各为多少
完全二叉树中 $n_1$ 只可能是 0 或 1,而 $n_0+n_2$ 必为奇数($n_0=1+n_2$),因此可以根据总结点数的奇偶性来确定 $n_1$,进而确定 $n_0$ 和 $n_2$
换言之,完全二叉树总结点数为 $2n$ 时,$n_0=n$, $n_1=1$,$n_2=n-1$;总结点数为 $2n-1$ 时,$n_0=n$, $n_1=0$,$n_2=n-1$
高度为 $h$ 的完全二叉树最少有 $2^{h-1}$ 个结点,最多有 $2^h-1$ 个结点
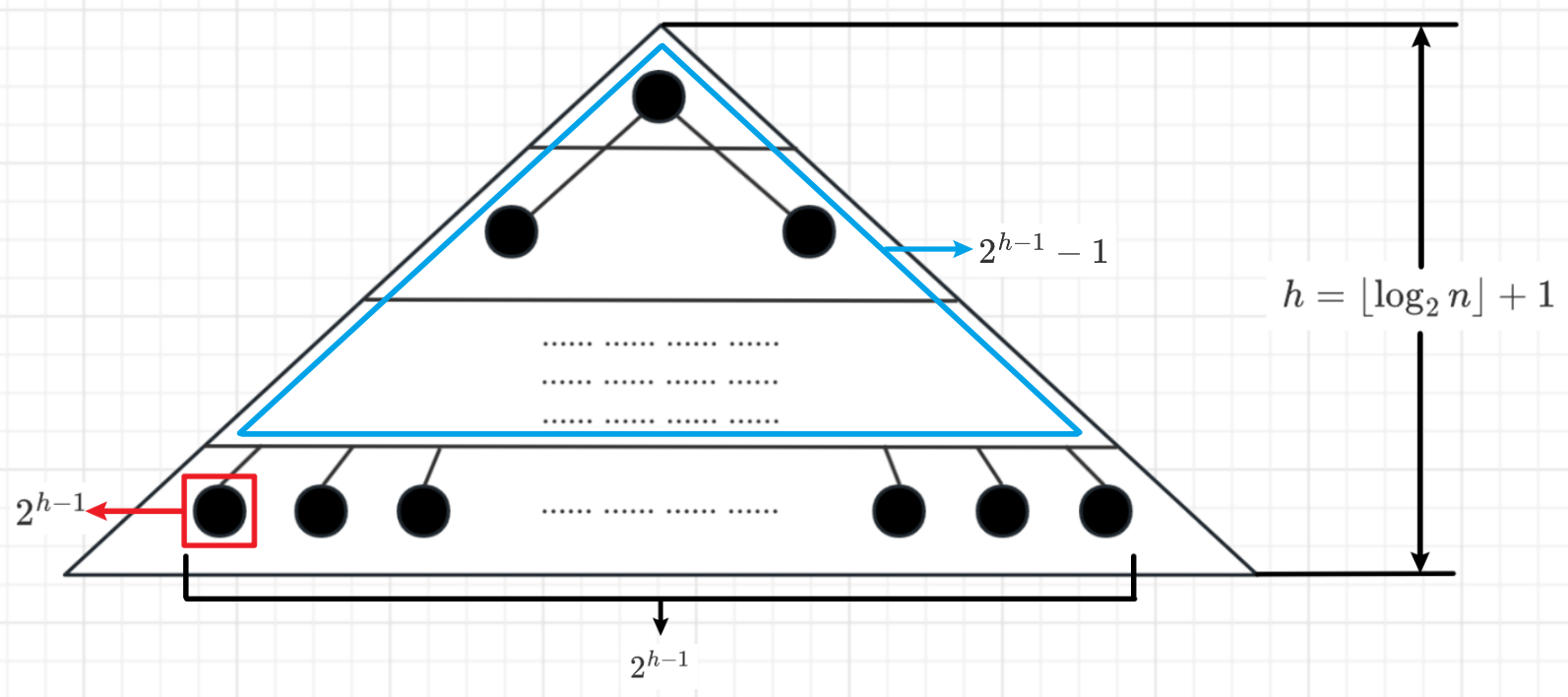
高度为 $h$ 的 $m$ 叉树至多有 $\frac{m^h-1}{m-1}$ 个结点
具有 $n$ 个结点的 $m$ 叉树的最小高度为 $\lceil\log_m(n(m-1)+1)\rceil$(二叉树为 $\lceil\log_2(n+1)\rceil$ 或 $\lfloor\log_2n\rfloor+1$)
满 $m$ 叉树
编号为 $i$ 的结点的双亲结点(若存在)的编号是 $\lfloor\frac{i-1}{m}\rfloor+1$
编号为 $i$ 的结点的第 $k$ 个孩子结点(若存在)的编号是 $(i-1)m+k+1$
编号为 $i$ 的结点有右兄弟的条件是 $(i-1)\% m \neq 0$
Catalan 数(卡特兰数)应用
$f(n)=\frac{C^n_{2n}}{n+1}=\frac{(2 n) !}{n !(n+1) !}$
1)$n$ 个不同元素入栈序列确定,并可在任意时刻出栈,可能的不同出栈序列数目
2)给定 $n$ 个结点,可能构成的不同(形态)二叉树数目
3)二叉树先序序列给定,可能的不同中序序列/二叉树数目
线索二叉树至多两个空链域,至少一个空链域
先序线索化后至少 1 个空链域(最右叶结点右链域),若根结点无左子树,则是 2 个空链域
中序线索化后有 2 个空链域(最左结点左链域、最右结点右链域)
后序线索化后至少 1 个空链域(最左叶结点左链域),若根结点无右子树,则是 2 个空链域
存在单树森林
对于一棵树:
“分支”数 = 叶结点数 = 有右兄弟结点数 + 1
非叶结点数 + 1 = 无右兄弟结点数(每个非叶结点的最右孩子以及根结点没有右兄弟)
树和森林只有两种遍历:先根、后根,对应二叉树遍历为:先序、中序
森林的后根遍历有时也叫后序遍历、中序遍历、中根遍历
考题默认哈夫曼树是二叉
不可能的哈夫曼编码:非前缀编码、频率和长度不匹配(实在不行就画)
最多编码:尽可能使叶结点都处于最底层
构造出哈夫曼树后算 WPL 时别把内部结点算上了
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ZERO!
